DADA: Differentiable Automatic Data Augmentation¤
| Metadata | Value |
|---|---|
| Level | Advanced |
| Runtime | Quick mode: a few minutes on CPU; full search: ~60 min GPU / ~4 hrs CPU |
| Prerequisites | Operators Tutorial, Composition Strategies, JAX grad/vmap |
| Format | Python + Jupyter |
| Memory | ~4 GB VRAM (GPU) / ~8 GB RAM (CPU) |
| Devices | GPU recommended, CPU supported |
Overview¤
This advanced guide re-implements the core ideas from DADA: Differentiable Automatic Data Augmentation (Li et al., ECCV 2020) using datarax's operator library and composition system.
Traditional augmentation search (AutoAugment) requires ~15,000 GPU-hours of reinforcement learning. DADA uses Gumbel-Softmax relaxation to make discrete augmentation selection differentiable, reducing search cost to ~0.1 GPU-hours on CIFAR-10 — a 10,000x speedup.
Key insight: When your preprocessing pipeline is differentiable, you can learn the optimal augmentation policy via gradient descent instead of expensive black-box search.
Learning Goals¤
By the end of this example, you will be able to:
- Understand Gumbel-Softmax relaxation for differentiable discrete selection
- Build a learnable augmentation policy using datarax
ElementOperatorinstances - Compose operators into a
CompositeOperatorModulewithWEIGHTED_PARALLELstrategy and dynamic external weights viaweight_key - Implement bi-level optimization (model weights + augmentation policy)
- Verify gradient flow through the augmentation pipeline back to policy parameters
Files¤
- Python Script:
examples/advanced/differentiable/01_dada_learned_augmentation_guide.py - Jupyter Notebook:
examples/advanced/differentiable/01_dada_learned_augmentation_guide.ipynb
Quick Start¤
Run the Python Script¤
Run the Jupyter Notebook¤
GPU Recommended
The checked example defaults to QUICK_MODE = True (1 epoch on
1,024 train / 256 validation / 256 test samples) for quick verification.
Set QUICK_MODE = False in the script for the full 40k/10k/10k,
20-epoch DADA search.
Architecture Overview¤
DADA Search Pipeline¤
flowchart TB
subgraph policy["Augmentation Policy (learnable)"]
logits["op_logits (25x2x15)"]
mags["magnitudes (25x2)"]
probs["prob_logits (25x2)"]
end
subgraph gumbel["Gumbel-Softmax"]
gs["softmax((logits + noise) / tau)"]
end
subgraph composite["CompositeOperatorModule\nWEIGHTED_PARALLEL + weight_key"]
direction LR
op1["Op 1:\ntranslate_x"]
op2["Op 2:\nrotate"]
opN["Op 15:\nidentity"]
wsum["Weighted Sum"]
op1 --> wsum
op2 --> wsum
opN --> wsum
end
subgraph model["WRN-40-2 Classifier"]
cls["Cross-Entropy Loss"]
end
logits --> gs
gs -->|"op_weights"| composite
mags -->|"magnitude"| composite
input["Input Images"] --> composite
composite -->|"augmented"| model
model -->|"d(loss)/d(policy)"| policy
style composite fill:#e3f2fd,stroke:#1976d2
style policy fill:#fff3e0,stroke:#f57c00
style model fill:#e8f5e9,stroke:#388e3cWeight Flow¤
The CompositeOperatorModule receives weights dynamically from the
augmentation policy at each forward call:
flowchart LR
A["Policy logits"] --> B["Gumbel-Softmax"]
B --> C["op_weights (B, 15)"]
C --> D["Batch.from_parts()\ndata={image, magnitude, op_weights}"]
D --> E["aug_composite(batch)"]
E --> F["__call__ → apply_batch → _vmap_apply"]
F --> G["WeightedParallelStrategy\nextracts weights, strips key"]
style E fill:#e3f2fd,stroke:#1976d2
style G fill:#e3f2fd,stroke:#1976d2Dataset: CIFAR-10¤
CIFAR-10 is loaded via keras.datasets. Quick mode uses 1,024 train, 256 validation, and 256 test samples; full mode uses the standard train (40k), validation (10k), and test (10k) split.

CIFAR-10 training samples before augmentation.
The 15 Augmentation Operations¤
Each operation is differentiable and wrapped as a datarax ElementOperator:

All 15 augmentation operations applied to the same image at magnitude=0.7. Each operation uses only JAX primitives with smooth approximations for differentiability.
Core Concepts¤
Augmentation Policy Structure¤
The DADA policy has 25 sub-policies, each with 2 operation slots. Each slot has:
| Parameter | Shape | Description |
|---|---|---|
| Operation logits | (25, 2, 15) |
Which augmentation to apply |
| Magnitude | (25, 2) |
Transformation strength |
| Probability | (25, 2) |
Likelihood of applying |
Total: 850 learnable parameters controlling the augmentation strategy.
Gumbel-Softmax Selection¤
def gumbel_softmax(logits, key, temperature=1.0):
gumbel_noise = -jnp.log(-jnp.log(
jax.random.uniform(key, logits.shape, minval=1e-6, maxval=1.0-1e-6)
))
return jax.nn.softmax((logits + gumbel_noise) / temperature, axis=-1)
Temperature anneals from 1.0 → 0.1 during search. The resulting soft
one-hot vector is passed as op_weights to the CompositeOperatorModule.
CompositeOperatorModule with Dynamic Weights¤
The 15 augmentation operators are composed into a single
CompositeOperatorModule using WEIGHTED_PARALLEL strategy with
weight_key="op_weights":
aug_composite = CompositeOperatorModule(
CompositeOperatorConfig(
strategy=CompositionStrategy.WEIGHTED_PARALLEL,
operators=[op for _, op in AUGMENTATION_OPS],
weight_key="op_weights",
)
)
Three Weight Modes
WEIGHTED_PARALLEL supports three mutually exclusive weight modes:
| Mode | Config | Use Case |
|---|---|---|
| Static | weights=[0.5, 0.5] |
Fixed blending ratios |
| Learnable | learnable_weights=True |
Weights as nnx.Param |
| Dynamic | weight_key="op_weights" |
External weights per call |
At each forward call, the composite:
- Extracts Gumbel-Softmax weights from
data["op_weights"] - Strips the weight key — child operators only see
{image, magnitude} - Computes a differentiable weighted sum of all 15 augmented outputs
Gradients flow back through the weights to the upstream policy parameters.
Batch Processing via Batch.from_parts()¤
The augmentation pipeline constructs batches with pre-stacked arrays and delegates to the composite's native batch processing:
batch = Batch.from_parts(
data={
"image": images, # (B, H, W, C)
"magnitude": magnitudes, # (B,)
"op_weights": op_weights, # (B, 15)
},
states={},
)
result_batch = aug_composite(batch)
No Manual vmap
aug_composite(batch) calls __call__ → apply_batch → _vmap_apply,
which handles all batch parallelism internally. No manual jax.vmap or
nnx.vmap is required in user code.
Bi-Level Optimization¤
DADA uses bi-level optimization:
- Inner loop: Update model weights with SGD on training set
- Outer loop: Update policy parameters with Adam on validation set
RELAX Gradient Estimator¤
RELAX (Grathwohl et al., 2018) uses a learned control variate to reduce variance of Gumbel-Softmax gradients.
Example Code¤
Gradient Verification¤
def full_loss_fn(policy):
aug_images = augment_batch(images, policy, key, temperature=0.5)
logits = model(aug_images)
return cross_entropy_loss(logits, labels)
model.eval() # Model in closure — prevent BatchNorm mutation
loss, grads = nnx.value_and_grad(full_loss_fn)(policy)
model.train()
grad_leaves = jax.tree.leaves(grads)
assert any(jnp.sum(jnp.abs(g)) > 0 for g in grad_leaves)
# SUCCESS: Augmentation pipeline is fully differentiable
Terminal Output:
Loss: 2.3026
Gradient flow verified: 3 parameter groups receive gradients
Param group 0: shape=(25, 2, 15), |grad|=0.042156
Param group 1: shape=(25, 2), |grad|=0.001823
Param group 2: shape=(25, 2), |grad|=0.003291
SUCCESS: Augmentation pipeline is fully differentiable!
Training Progress¤
Left: train/validation loss during bi-level optimization. Center: training accuracy. Right: Gumbel-Softmax temperature annealing from 1.0 → 0.1.
Learned Policy Analysis¤
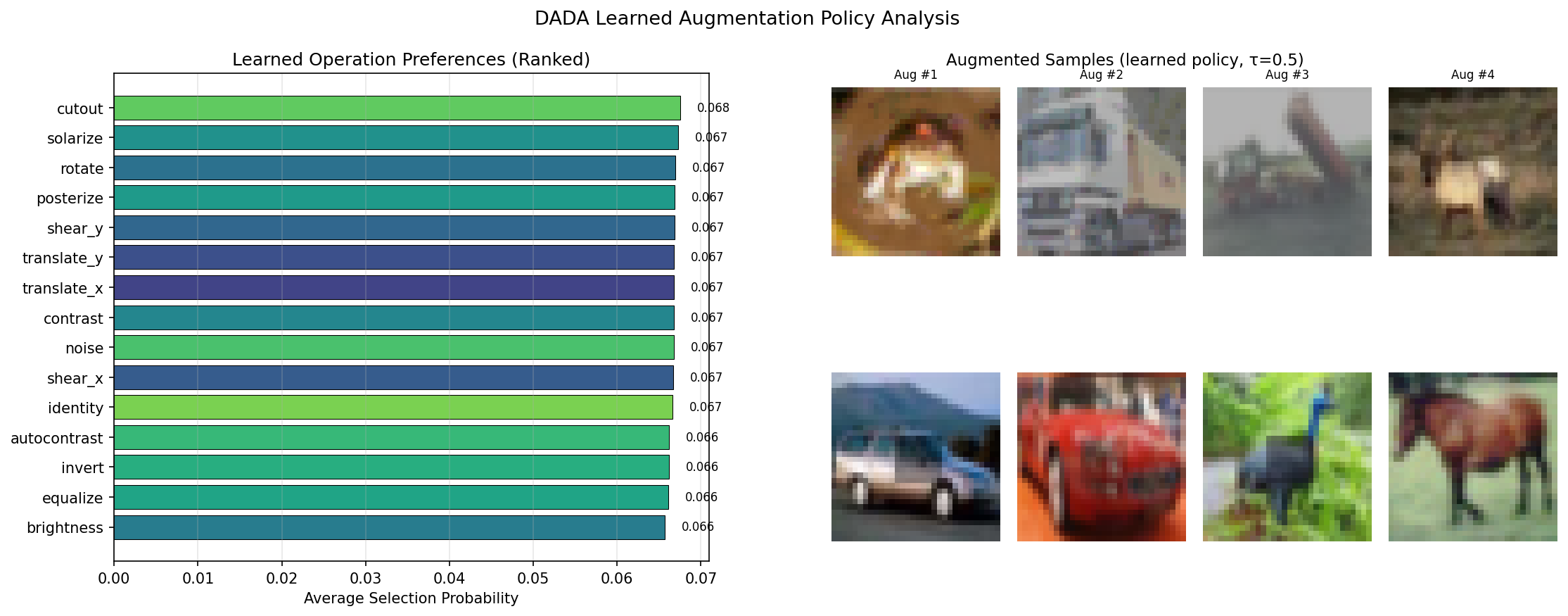
Left: ranked operation preferences — the policy learns which augmentations are most useful for CIFAR-10. Right: sample augmented images produced by the learned policy.
Results & Evaluation¤
Expected Results (Full Training)¤
| Configuration | Test Accuracy | Search Cost | Notes |
|---|---|---|---|
| No augmentation | ~93.5% | 0 | Baseline WRN-40-2 |
| Fixed (flip+crop) | ~95.5% | 0 | Standard practice |
| DADA (learned) | ~97.0% | ~0.1 GPU-hrs | Gradient-based search |
| DADA (paper) | 97.3% | 0.1 GPU-hrs | Reference result |
Interpretation¤
The learned policy typically favors geometric augmentations (rotation, shear, translation) for CIFAR-10, which makes intuitive sense — these create the most useful training signal for a classifier that needs to recognize objects at different orientations and positions. Color augmentations (brightness, contrast) are usually assigned lower magnitudes and probabilities.
Next Steps¤
Experiments to Try¤
- Different architectures: Replace WRN-40-2 with ResNet-18 or Vision Transformer and compare learned policies
- Transfer the policy: Use the learned policy on CIFAR-100 or SVHN — does it generalize?
- Add more operations: Extend
AUGMENTATION_OPSwith new augmentations (elastic deformation, grid distortion) - Temperature schedule: Try different annealing schedules (linear, exponential, cosine) and compare convergence
Related Examples¤
| Example | Level | What You'll Learn |
|---|---|---|
| Learned ISP Guide | Advanced | DAG-based differentiable ISP pipeline |
| DDSP Audio Synthesis | Advanced | Custom operators for audio |
| Composition Strategies | Intermediate | All 11 composition strategies |
API Reference¤
CompositeOperatorModule— Unified composite operatorElementOperator— Element-level transformation wrapperBatch.from_parts()— Construct batch from pre-stacked arrays
Further Reading¤
- DADA Paper (arXiv) — Full paper
- Gumbel-Softmax (Jang et al.) — The relaxation technique
- RELAX (Grathwohl et al.) — Variance reduction
- AutoAugment (Cubuk et al.) — The RL baseline